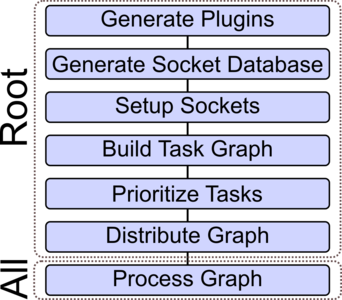
Distributed Data Parallel Mode Scheduler
The DDPM scheduler kernel enables simulations based on the data parallel approach. The following figure depicts the flow diagram of the scheduler implementation. Contrary to the DTPM scheduler, the graph is not partitioned as all plugins are processed by all MPI processes in the same sequence. The root process prepares the task graph and generates a prioritized list of plugins. This list is distributed to all MPI processes each processing the graph in its entirety. As with the DTPM scheduler, each MPI process holds its own socket database responsible to store the data associated with the sockets on the local process.
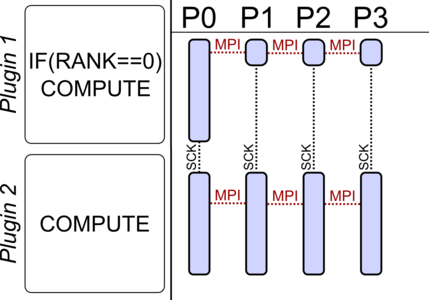
In the following the execution behavior of the scheduler is shown. Each plugin is processed by all MPI processes and has access to an MPI communicator. Inter-plugin communication is provided by the socket data layer, whereas inter-process communication is supported by the MPI library.